
ArXiv
Preprint
Source Code
Github
What is Paint by Word?
Paint by Word allows you to use words to create an AI paintbrush. For example, if you want to make a piece of furniture look rustic, you can use the words "rustic bed" to define a paintbrush that can modify a bed to take on that style. Or use other words and paint other objects, as shown in the example below.
| In this area... | ... Paint this word: | ||||
|---|---|---|---|---|---|
| (user-painted) | Metallic | Rustic | Purple | Floral | |
Window |
 |
 |
 |
 |
 |
Bed |
 |
 |
 |
 |
 |
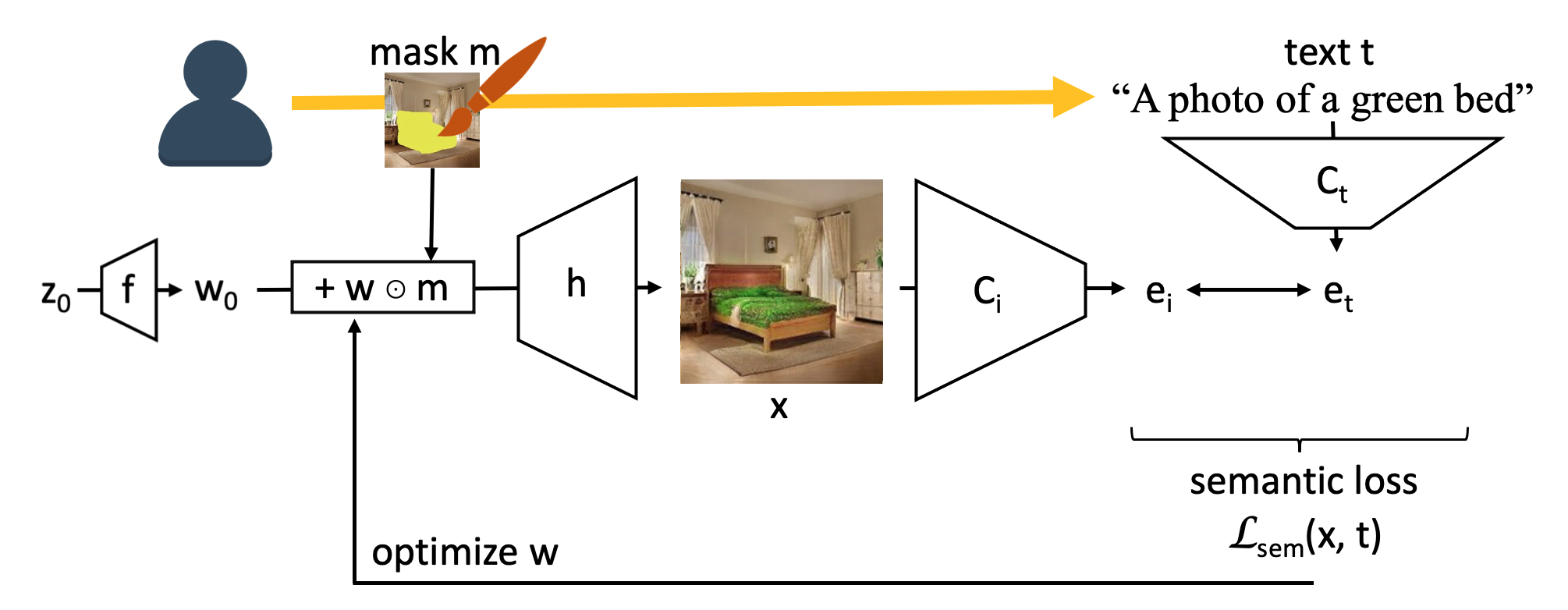
How does Paint by Word Work?
Paint by Word pairs an image generator such as StyleGANv2 (Karras, et al 2019) or BigGAN (Brock, et al 2018) with the recent CLIP network from OpenAI (Radford, et al 2021). We split the image generator to allow the region painted by the user to be separately controlled, and then we modify the generator's representation of the region to match the words given by the user, by maximizing the score given by CLIP.
The approach is remarkably simple: both networks are taken off-the-shelf without fine-tuninig to the task. Both networks were originally trained on simpler problems: CLIP does not know how to edit or generate an image on its own, and the GAN does not know about anything about language on its own.
What do we learn?
It is interesting to find that a pair of models that were not trained together can acheive good results on a difficult task by just guiding one another. To create accurate, realistic, targeted results, we make two key observations:
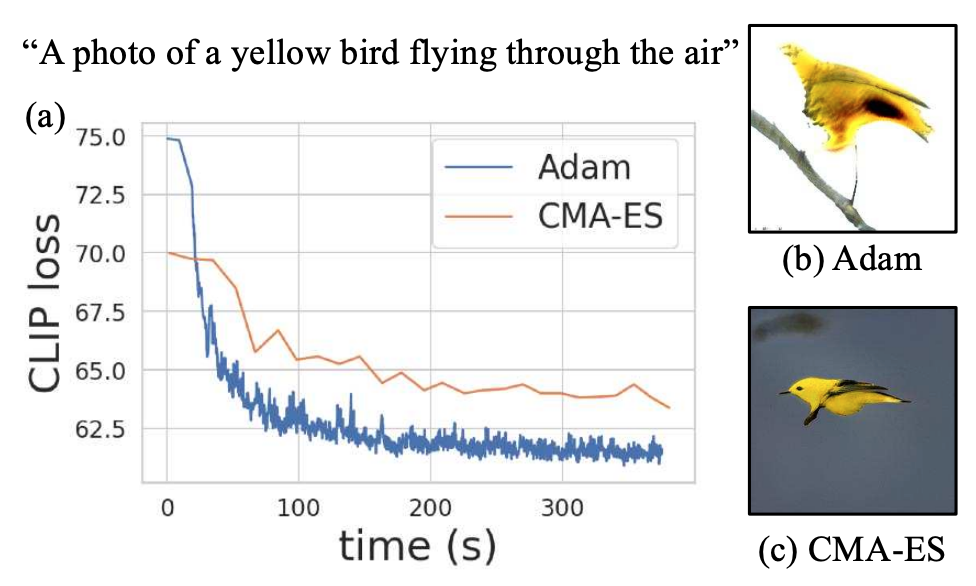
- Results are more realistic and accurate when optimizing a distribution
of images to the objective, rather than overfitting a single image. We find
that Covariance Matrix Adaptation (CMA-ES)
yields better results than
gradient descent, and good enough to achieve state-of-the-art on
a standard benchmark of bird descriptions.
- Targeting changes to a specific user-provided region can be
done by splitting the generative model spatially, so
that the area inside the user region is represented using a different
latent from the area outside the region.

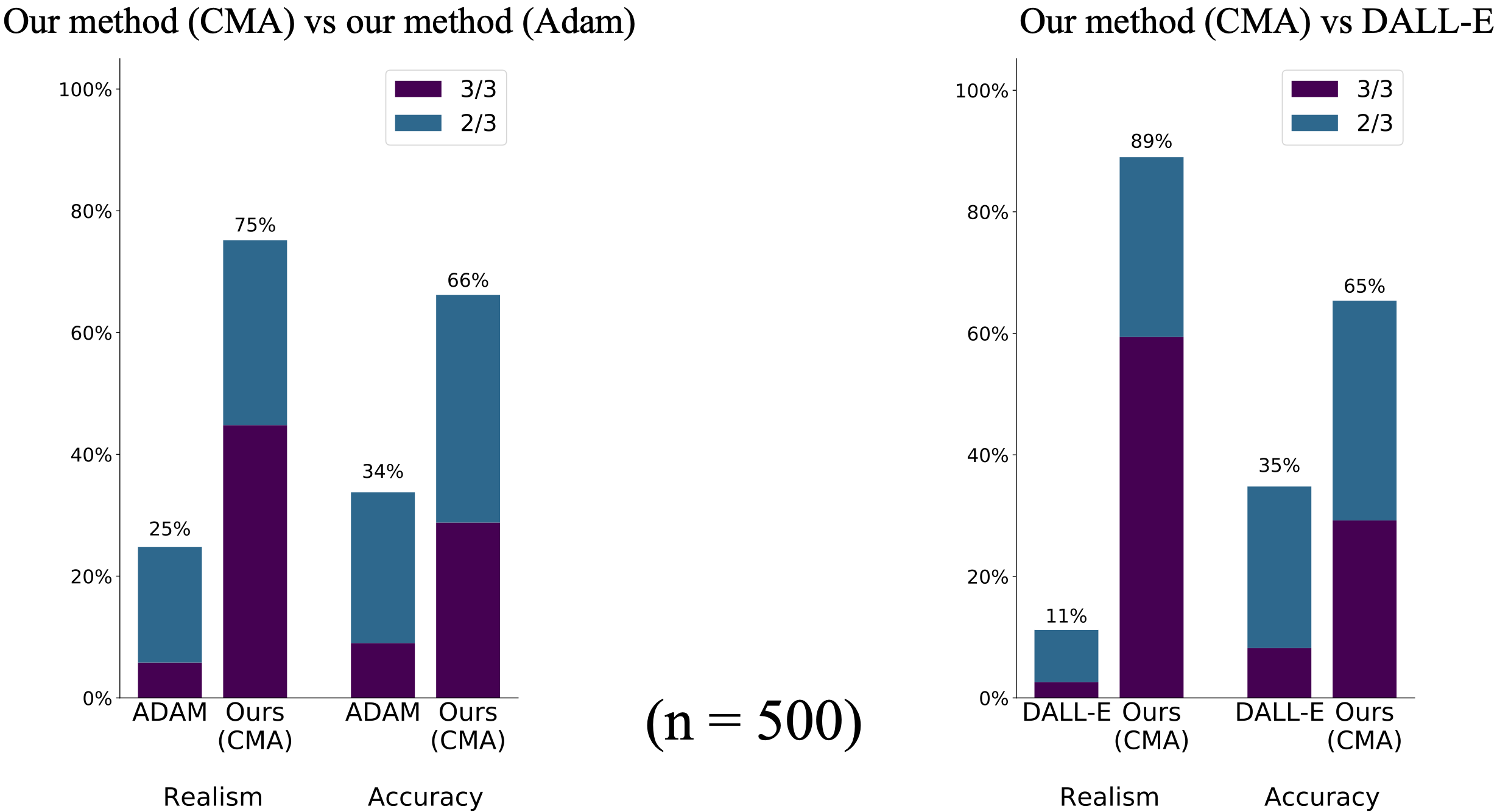
Benchmarking realism and accuracy
One of the standard ways to evaluate accuracy and realism on the difficult text-to-image task is to generate images of birds based on a set of English captions of birds based on the CUB birds dataset. We evaluated our method on this test by training a StyleGANv2 on CUB birds and painting the full image using the caption words.

Our method yields strong results on this benchmark, outperforming the bird images synthesized previous state-of-the-art DALL-E method (Ramesh, et al. 2021) when rated by humans. In the evaluation below, five hundred synthesized images are each evaluated by three people for realism (which method looks more like a real photograph?) and accuracy (which image is a better match for the text?)
More examples of editing
How to Cite
bibtex
@misc{bau2021paintbyword,
title={Paint by Word},
author={Alex Andonian and Sabrina Osmany and Audrey Cui and YeonHwan Park
and Ali Jahanian and Antonio Torralba and David Bau},
year={2021},
eprint={arXiv:2103.10951},
}